
Each summer, the University of Rhode Island Graduate School of Oceanography (GSO) hosts undergraduate students from all over the country to participate in oceanographic research. These Summer Undergraduate Research Fellows (SURFOs) have not only been working with GSO scientists, but they also have spent part of their time learning how to communicate this science to the public.
Our guest author today is Katharina Gallmeier, who writes: I am a fourth-year undergraduate student studying applied physics at Columbia University in NYC! My goal has always been to help combat the climate crisis to my best ability, and so far, in college, I’ve been figuring what I like and don’t like to do. This summer, for example, I played around with large remote sensing datasets to see whether that type of work, which involves lots of computer programming, is something I enjoy!
Read on to find out what Katharina has been up to, and why everyone should be excited about her work.
Models help us see the future ocean
The future has always been an uncertain business, but when it came to Earth’s climate, we humans thrived in knowing what seasons came when and how to prepare for it. Today, we are not sure how the climate on Earth will evolve. Reproducing known conditions is by itself difficult and computationally expensive. Add to that the fact that our present and future actions may still have some effect in mitigating the change, and it is easy to resign.
Bettering our ability to predict climate change involves improving upon the existing numerical models or developing new ones. Of particular interest and need is modeling the ocean which absorbs much of the trapped heat and emitted greenhouse gases in Earth’s atmosphere. Such a model for the ocean is called an Ocean General Circulation Model. OGCMs aim to reproduce mechanisms influencing the global evolution of the ocean’s physical properties, such as temperature, salinity, and velocity.
Details matter
The development of these models is hampered by two big –or maybe little—questions: of what size are the relevant physical processes driving the ocean’s general circulation and how do we best incorporate them? We know that scale matters in the dynamics of ocean energy: energy within fluids not only travels down from large scale to small scale, as when kinetic energy of a strong current eventually leads to heat being generated by rubbing water molecules. Plus, smaller scale phenomena, like turbulence, can spur larger scale processes in a non-obvious way. What we don’t know is how high a spatial resolution we need for effective OGCMs.
There’s a danger of only looking at how well OGCMs depict large-scale ocean patterns, because it’s important to see how well it captures small-scale dynamics, too. We can evaluate an OGCM by examining how well it reproduces the small-scale processes in real world data. To do so requires a dataset of equally high or higher resolution, global coverage, and of a physical parameter that the model outputs. Only sea surface temperature (SST) datasets from satellites fulfill these three requirements. By comparing modeled and observed SST data, we can assess how well OGCMs are working.
A big task for a short summer
This is how I spent my summer. I compared the SST outputs from the highest-resolution OGCM I could find to SST data from a satellite. To study the small-scale processes, we extracted 128 x 128 km images from five-minute SST data chunks; look below! We call these extracted images “cutouts” because we literally cut out smaller images from the larger image.
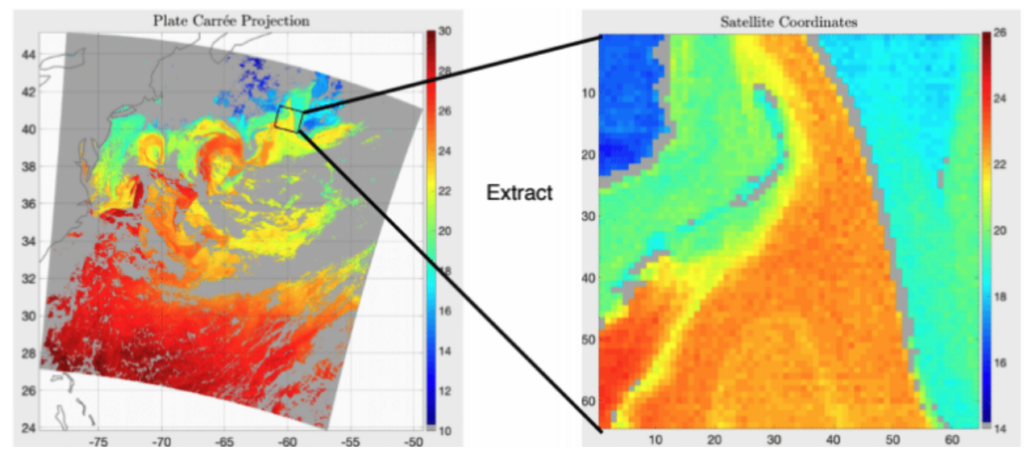
In my project, I used year-long SST datasets. A year’s worth of SST data contains 300,000 cutouts of 4096 pixels each. Multiply that by ten, and a decade’s worth of SST data gives one over 3 million cutouts! Working with huge amounts of data limits us to using a statistical approach than a visual comparison of image pairs. There are simply too many to look through each one individually to first find out which images one should compare and then note down what one sees!
Who saves the day?
Because we had no army of people at hand to sift through them all, we let a machine learning algorithm capture the SST patterns in the cutouts and assign each cutout a characteristic number of how likely it is to be found in a full dataset. What do I mean by full? A full dataset, defined in this article, has data from around the entire globe (spatially full) and from at least one entire year (temporally full).

Now what?
Working with a single characteristic value rather than an entire image is significantly easier, right? Yes and no. We can easily pinpoint differences and similarities between satellite data and model outputs, but it’s harder to figure out why they exist.
To identify the spatial differences and similarities, I divided the globe into approximately 40,000 100×100 km squares. In each square, I calculated the median characteristic value of the cutouts that were located within and took the difference between the model and satellite’s median values. The results are plotted below.
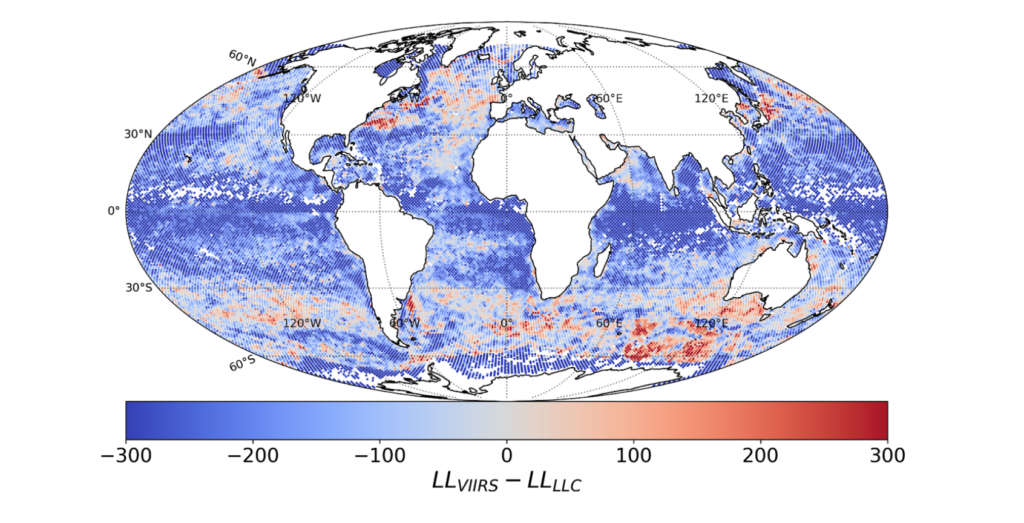
That’s the easy step! Figuring out why the numerical model produces similar/different cutouts than what the satellite observes requires looking into each area in detail. And that’s way harder!
Where does this take us?
The potential of this project is huge, especially as we better learn how the machine learning model converts cutouts into characteristic numbers. Simply pointing out where the model and satellite data differ is the first step in helping those who are model developers, those who work on satellite data retrieval algorithms, and those who use information given by the model or data.
Notably, the OGCM I’m looking at will be used in the National Aeronautics and Space Administration’s mission to predict climate change. For that reason, it is vital to make sure this OGCM accurately describes large-scale events in the ocean. Keep in mind a model is only as good as its small-scale predictions too!
Hello! I’m a third-year PhD student at University of California, Davis, in the Center for Environmental Policy and Behavior. My research focuses on how coastal communities make decisions around climate change adaptation. I’m lucky to get to explore this question across the West Coast (school!) and the East Coast (home!). When not PhD-ing, I’m happiest when reading, writing, backpacking, or gazing at the sea– whether that’s the Pacific or the Atlantic.

